Site Architecture Mistakes That Kill Enterprise SEO During Migrations: A Recovery Playbook
Enterprise site migrations fail because of architecture decisions made months before launch, not because of the cutover itself. The most documented case: a UK retailer lost £3.
 Marcus Webb··9 min read
Marcus Webb··9 min read
Site Architecture Mistakes That Kill Enterprise SEO During Migrations: A Recovery Playbook
Enterprise site migrations fail because of architecture decisions made months before launch, not because of the cutover itself. The most documented case: a UK retailer lost £3.8 million in organic revenue within 30 days after its IT consultants overruled the SEO team's redirect strategy, as reported by iPullRank and Nument.
That single case has become a reference point across the migration consulting world. But what gets lost in the retelling is how the failure cascaded through the information architecture, why the hired consultants missed every warning signal, and what specific competencies the retailer should have screened for in their RFP. I've evaluated over 200 SEO agencies and consultancies, and the pattern I see most often in migration disasters is a hiring problem masquerading as a technical one. Companies bring in the wrong team, give them the wrong scope, and discover the damage 60 to 90 days after launch when the organic revenue cliff becomes impossible to ignore.
Search Engine Journal's analysis of 892 enterprise migrations found a 523-day average recovery time to reach pre-migration organic traffic levels. 17% of sites in that dataset never fully recovered, even after 1,000 days of remediation. Only about 10% of migrations actually improved SEO performance. These numbers should terrify any enterprise leader signing off on a replatform project.
The Retailer's IT Consultants Called the Redirect Map "Too Complex"
The UK retail case unfolded the way most enterprise migration disasters do: a well-funded replatform project staffed by technically competent people who didn't understand search architecture. The company hired IT consultants to manage a CMS migration. The SEO team produced a full redirect map covering thousands of legacy URLs accumulated over years of operation. The IT consultants looked at the map, decided it was unnecessarily complicated, and launched the new platform without implementing it.
According to Hashmeta's enterprise CMS migration guide, "many organizations underestimate the redirect complexity of enterprise sites. Thousands of pages may have accumulated over years, including content you forgot existed. Incomplete redirect maps create 404 errors that damage user experience and SEO." The retailer's case is the extreme version of this underestimation: the map wasn't incomplete, it was rejected entirely.
The financial damage of £3.8 million ($5 million USD) materialized within a single billing cycle. Organic traffic dropped over 50%, consistent with what Outpace SEO's migration checklist calls "a few predictable errors" that account for most migration failures. The retailer had indexed thousands of product pages, category pages, and informational content. Every single one of those URLs started returning 404 errors the moment the new site went live.

If you've read through our complete 301 redirect and authority preservation playbook, you know that redirect mapping is the single most load-bearing element of any migration. Skipping it is the architectural equivalent of removing load-bearing walls during a renovation and wondering why the ceiling collapses.
Three Architecture Failures That Compounded in Week One
The redirect rejection was the catalyst, but the damage didn't stop there. Enterprise site migrations fail in layers, and this case demonstrated three compounding architecture failures that I now screen for whenever I evaluate an agency's migration capabilities.
Failure 1: Content silo restructuring without equity mapping. The new platform reorganized the site's category taxonomy. Product pages that lived under /electronics/televisions/brand-name were flattened into /shop/brand-name with no intermediate category structure. This content silo restructuring destroyed the topical authority signals Google had associated with the old hierarchy. The Nielsen Norman Group's research on information architecture mistakes describes this exact problem: "the profusion of options also makes people question the information scent. This lack of confidence early in the site experience extends throughout their visit and can negatively impact the end result." The retailer's new architecture offered less topical clarity to both users and search engines.
Failure 2: Internal linking infrastructure collapsed. The migration broke over 2,000 internal links. Navigation menus, footer links, contextual in-content links, breadcrumb trails: all of them pointed to URLs that no longer existed. A separate retail case documented by Nav43 showed a 23% organic traffic decline over six months from broken internal links alone. The UK retailer experienced this same decay on top of the redirect catastrophe. When you're thinking about mapping authority flow before anyone touches your site, this is exactly the scenario you're trying to prevent.
Failure 3: Structured data and canonical tags stripped during the platform swap. The new CMS templates didn't carry over Schema.org markup, canonical tags, or optimized meta descriptions from the old platform. Every product page lost its rich snippet eligibility. The canonicalization gaps created duplicate content signals across hundreds of pages.
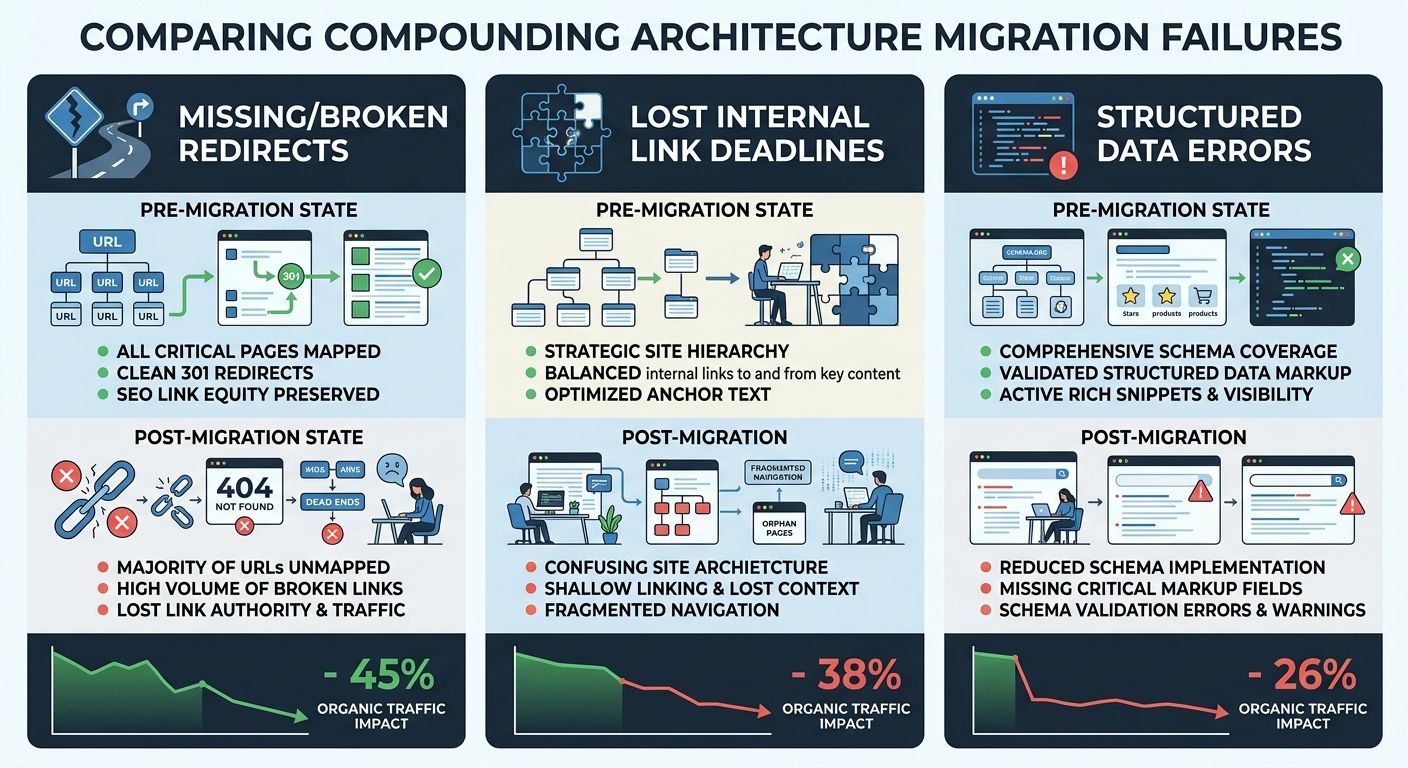
Each of these failures is individually recoverable within a few weeks. Together, they created an information architecture migration risk profile so severe that Google essentially had to re-crawl and re-evaluate the entire domain from scratch. And re-evaluation at enterprise scale, with thousands of pages, doesn't happen quickly.
Berlitz's Migration Team Made the Opposite Decision
Berlitz, the global language education company, executed a multi-region enterprise migration that serves as the cleanest counter-example to the UK retailer's failure. According to Urllo's documentation of the Berlitz migration, Berlitz's team "centralized redirect management" and maintained "thousands of permanent redirects as stable infrastructure rather than scattered configuration rules. This preserved link equity, prevented legacy URLs from turning into crawl errors and ensured long-term continuity across domains and regions."
The critical phrase there is "stable infrastructure." Berlitz's team didn't treat redirects as a migration checklist item to complete and forget. They built redirect management into the ongoing operational architecture of the site. At enterprise scale, URLs change constantly: products get discontinued, content gets consolidated, regional domains get restructured. The redirect layer has to be permanent and actively maintained.
The contrast between the two cases reveals the hiring question at the center of every enterprise site migration architecture project. The UK retailer hired IT consultants who viewed the migration as a platform swap: move the code, move the content, ship it. Berlitz hired (or assembled) a team that understood migrations as SEO infrastructure projects with a platform swap component.
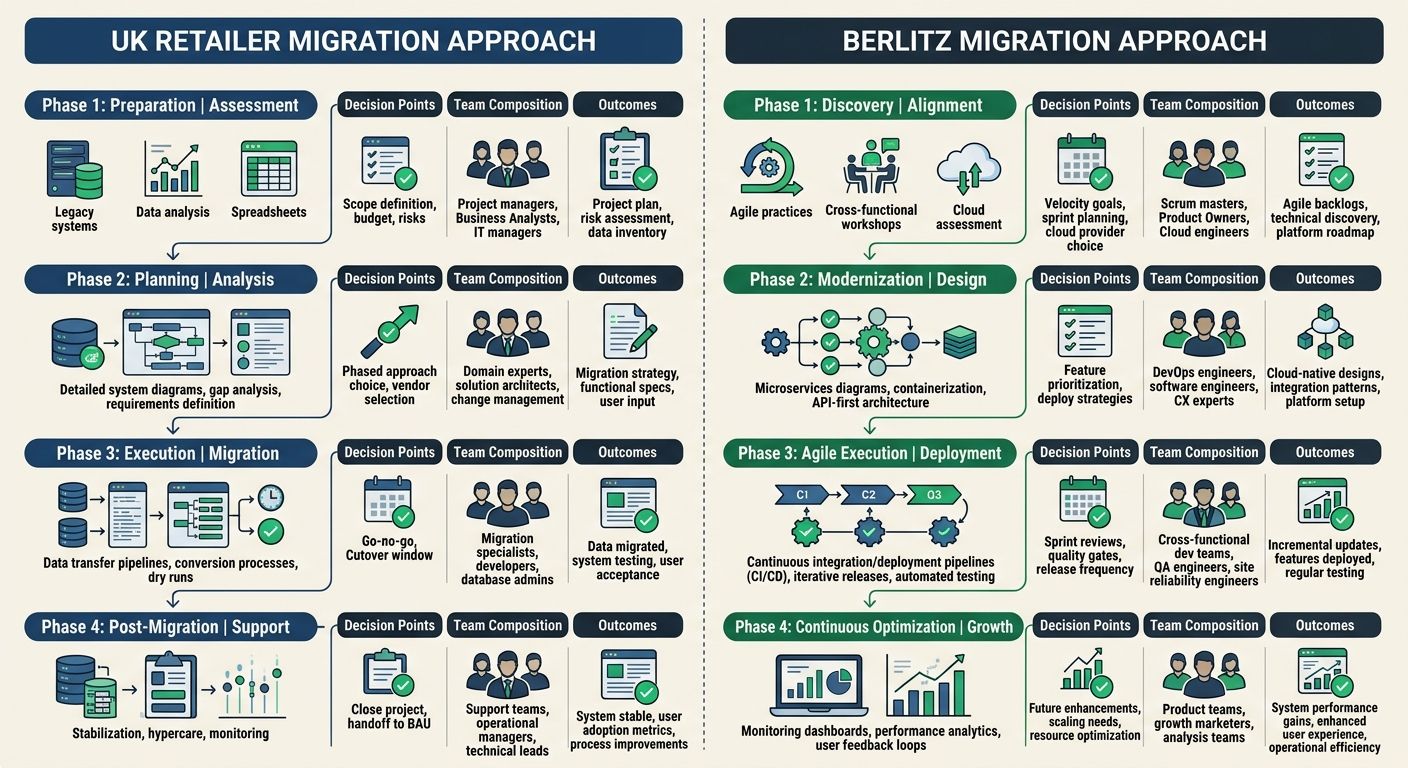
Concrete CMS's content migration best practices guide captures the mindset difference well: some content "transfers intact," other content "is worth improving," and then "there's content worth cutting entirely: outdated announcements, superseded policy documents, duplicate pages." A migration-competent team treats the project as an opportunity to fix legacy architecture problems, not just replicate them on a new platform. Berlitz's team understood this. The UK retailer's hired consultants didn't.
The Migration RFP Questions This Case Exposes
I've reviewed migration proposals from agencies charging anywhere from $15,000 to $500,000 for enterprise replatforms. The price difference doesn't always correlate with competence. What does correlate is how specifically the agency addresses site structure SEO recovery planning before the migration happens, and whether they've staffed the project with people who understand both the platform engineering and the search architecture simultaneously.
Based on the failure patterns in the UK retailer case and the success patterns in the Berlitz migration, here are the vetting questions I now use when evaluating agencies for enterprise migration work:
"Walk me through your redirect audit process for a site with 10,000+ indexed URLs." The right answer involves crawling the full legacy site (Screaming Frog or equivalent), cross-referencing with Google Search Console's indexed pages list, mapping every URL with any organic traffic or backlink equity to its closest new equivalent, and testing the full map in staging. If the agency talks about "automated redirect rules" without mentioning manual review of high-value pages, that's a red flag. Agencies that have handled real enterprise migrations know that automated rules catch about 70% of cases, and the remaining 30% require human judgment about content equivalence.
"How do you preserve content silo structure when the new platform uses a different taxonomy?" This question surfaces whether the agency understands how SEO silos function and whether they've thought about the relationship between URL structure, internal linking patterns, and topical authority. The answer should reference mapping the old taxonomy to the new one at the category level before touching individual pages.
"What's your plan for the first 14 days after cutover?" Outpace SEO's migration playbook recommends daily monitoring of the top 50 to 100 keywords and crawl errors for the first two weeks, with 5% to 15% traffic fluctuation considered normal and recovery to 95% to 100% of baseline expected by weeks 8 through 12 for well-executed migrations. Agencies that describe "weekly check-ins" for the post-launch period aren't operating at enterprise migration pace. You need daily triage capability.
"Show me a migration you've done where organic traffic dropped post-launch. What happened and how did you recover?" Every honest agency has a case like this. The ones that won't share one either haven't done enough migrations to encounter problems, or they aren't being transparent about their track record. The quality of the answer tells you more than any pitch deck.
If your enterprise SEO benchmarking is already sophisticated, you'll want to pressure-test whether the agency's performance metrics align with yours before migration work begins. Disagreements about what "recovery" means (traffic volume? keyword rankings? revenue attribution?) create enormous post-launch friction.
Vetting Criterion | Red Flag Answer | Green Flag Answer |
|---|---|---|
Redirect strategy | "We'll set up pattern-based rules" | "We crawl every indexed URL and map high-value pages manually" |
Content silo planning | "We'll replicate the current structure" | "We'll audit topical clusters and map taxonomy changes before migration" |
Post-launch monitoring | "Weekly reports for 90 days" | "Daily crawl error and ranking checks for 14 days, then weekly through day 90" |
Internal link audit | "The CMS handles navigation automatically" | "We audit contextual links, breadcrumbs, and footer links separately from navigation" |
Structured data migration | "The new templates include Schema" | "We map every Schema type from old to new and validate in staging" |
Eighteen Months Before Organic Traffic Stabilized
The 523-day average recovery figure from Search Engine Journal's study of 892 migrations isn't abstract. The UK retailer's recovery trajectory tracked close to that average. The immediate post-launch triage took roughly 4 weeks: identifying the missing redirects through Google Search Console's crawl error reports, implementing emergency 301 redirects for the highest-traffic URLs, and fixing the most critical broken internal links.
But the architecture damage went deeper. The content silo restructuring mistakes couldn't be undone with redirects alone. Google had to re-crawl and re-evaluate the site's topical authority under the new URL structure. That process, for a site with tens of thousands of pages, took months. The SEO debugging framework we've outlined before applies here: diagnosing whether the ongoing traffic depression was an indexation issue, a ranking issue, or a crawl efficiency issue required continuous iteration.
The retailer's recovery also illustrates why the 90% migration failure rate is so persistent. As Evolving Web's information architecture analysis notes, refreshing your architecture is valuable "especially if it hasn't kept pace with your content creation pipeline." But refreshing architecture during a migration means changing two variables simultaneously, and when traffic drops, you can't isolate which change caused which loss. The UK retailer changed their platform and their architecture at the same time. Separating those two projects would have reduced the failure surface dramatically.
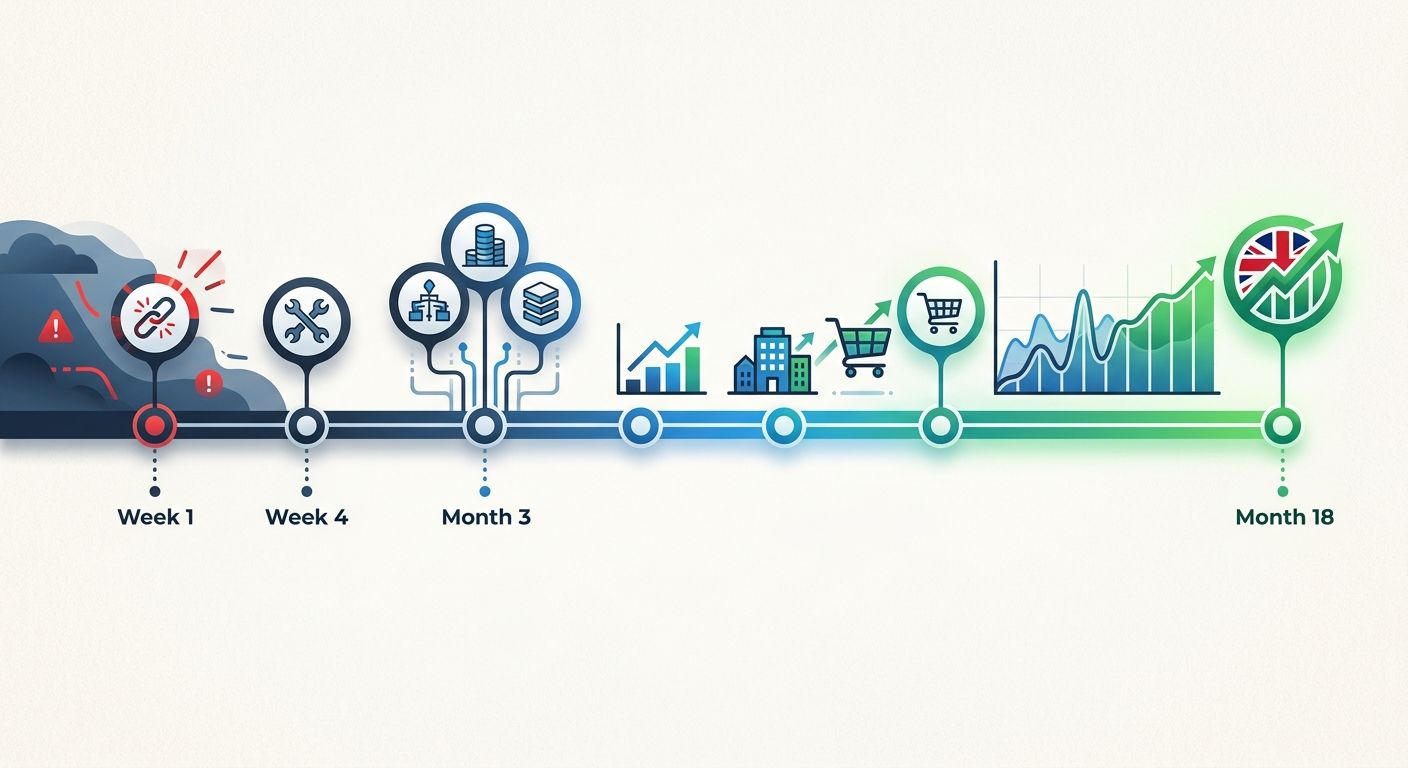
The retailer eventually recovered to approximately 90% of pre-migration organic traffic levels. That remaining 10% represents permanent equity loss from pages that were never properly redirected, backlink signals that dissipated during the 404 window, and content silos whose topical authority never fully reconstituted under the new taxonomy.
For enterprise leaders evaluating migration partners, this case distills into a single hiring principle: the team that migrates your site architecture needs to understand search architecture at least as well as they understand platform architecture. If your RFP doesn't weight SEO migration competence as heavily as CMS implementation experience, you're replicating the conditions that led to a £3.8 million loss. And you're likely looking at 18 months of recovery work that will cost more than doing it right the first time.
Marcus Webb
Digital marketing consultant and agency review specialist. With 12 years in the SEO industry, Marcus has worked with agencies of all sizes and brings an insider perspective to agency evaluations and selection strategies.
Related Articles
The Website Migration SEO Checklist: Pre-Launch Technical Validation That Prevents 90% of Ranking Loss
Pre-launch technical validation centered on 301 redirect integrity, staging crawlability, and traffic-weighted URL prioritization prevents the vast majority of organic ranking loss during website migrations.
Website Domain Migration Without Ranking Loss: The Complete 301 Redirect and Authority Preservation Playbook
A domain migration preserves rankings when three things execute correctly: complete 1:1 URL mapping with permanent 301 redirects, a pre-migration technical SEO audit that benchmarks every ranking signal worth protecting, and aggressive post-launch monitoring for at least 12 weeks.
Website Migrations Trigger 50% Traffic Drops That Persist Up to 18 Months When SEO Teams Miss Launch Window, Analysis Shows
Website migrations that exclude SEO teams during planning cause organic traffic drops exceeding 50 percent and require 12 to 18 months of recovery work, according to a Search Engine Journal technical analysis published June 5, 2026. The research distinguishes normal post-migration volatility (10-30
Explore more topics