Prepare Your Site Architecture for AI Crawlers: A 2026 Technical SEO Audit Beyond Rankings
Cloudflare's Q1 2026 Radar data puts AI crawlers at 30.6% of global web traffic, and in my audit work this year, I've found that roughly seven out of ten client sites have no deliberate robots.txt policy for a single one of those bots.
 Marcus Webb··10 min read
Marcus Webb··10 min read
Prepare Your Site Architecture for AI Crawlers: A 2026 Technical SEO Audit Beyond Rankings
Cloudflare's Q1 2026 Radar data puts AI crawlers at 30.6% of global web traffic, and in my audit work this year, I've found that roughly seven out of ten client sites have no deliberate robots.txt policy for a single one of those bots. GPTBot, ClaudeBot, PerplexityBot, and the newer Google-Agent are hitting servers daily, parsing content, and deciding whether to cite it in AI-generated answers. The sites that haven't prepared their architecture for this traffic are already invisible in a channel that's growing faster than organic search did in its first decade.
That invisibility is the reason I wrote this audit checklist. The traditional technical SEO audit checklist catches indexing errors, broken canonicals, and Core Web Vitals regressions. It does not catch the fact that four out of six major AI crawlers can't render JavaScript, or that your robots.txt is silently blocking the one crawler that would have cited your pricing page in a ChatGPT answer. This guide covers the architecture decisions that determine whether AI systems can find, read, understand, and cite your content.
Why Your Current Audit Framework Misses AI Crawlers
The standard crawl-and-index audit assumes Googlebot is the primary consumer of your site. Googlebot renders JavaScript. It respects canonical tags. It follows a well-documented set of behaviors that SEOs have spent two decades learning.
AI crawlers don't follow those same rules. ClaudeBot crawls 20,600 pages for every single referral visit it sends back. GPTBot's ratio is roughly 1,300 to 1. Meta's crawler returns zero referrals. These are fundamentally different consumption patterns, and they demand a different audit approach.
I evaluated a mid-market ecommerce site earlier this year that had strong traditional SEO metrics: clean crawl budget, fast load times, solid internal linking. But their entire product catalog was rendered client-side with React. When I pulled the raw HTML (no JavaScript execution), every product page was a skeleton with a loading spinner. Googlebot saw the products. Every AI crawler saw nothing. Their site structure for AI crawlers was, functionally, an empty shell.
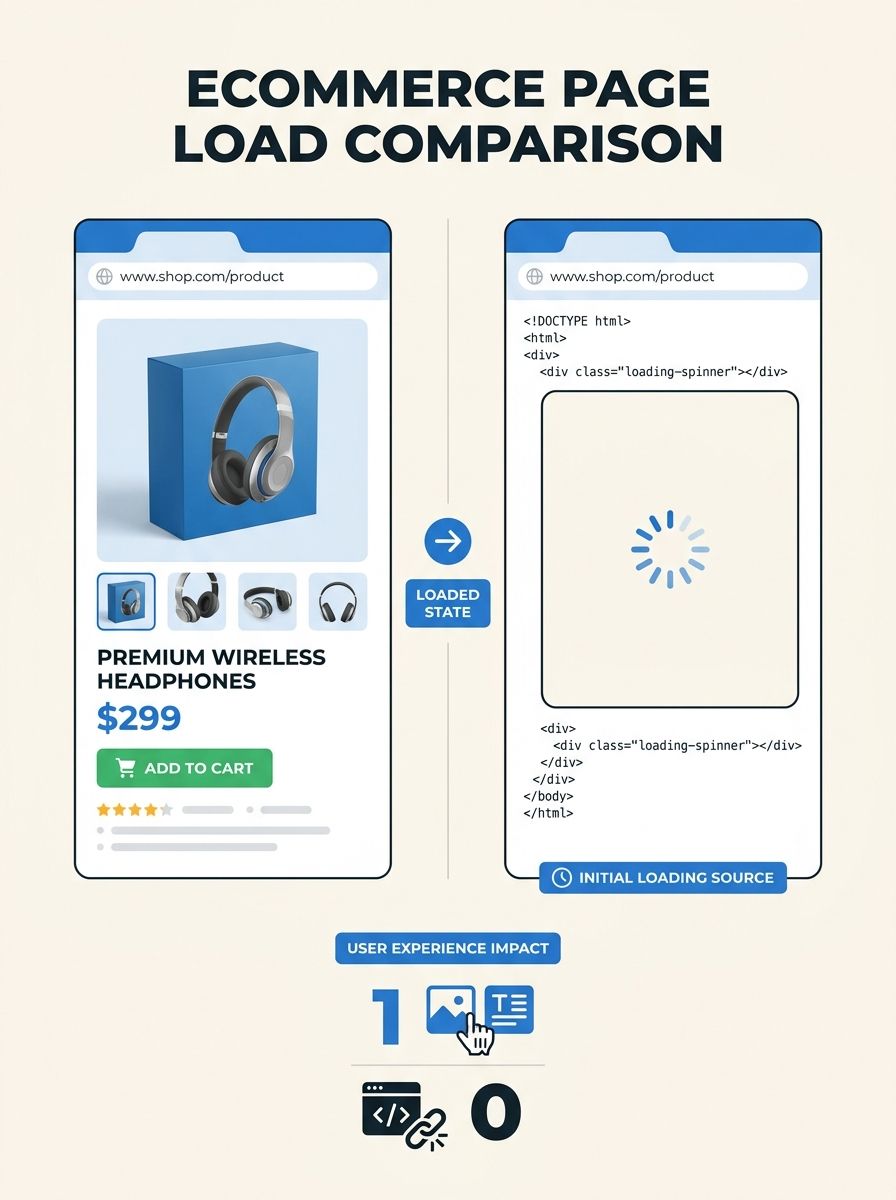
That's the gap this audit checklist addresses. If you've been following the conversation around how structured data gaps create AI visibility problems, this goes deeper into the architectural layer underneath.
Step 1: Audit and Customize Your robots.txt for Each AI Crawler
Blanket allow or blanket block policies are the default on most sites I audit. Both are wrong. You need per-crawler decisions based on the value exchange each bot offers.
Here are the AI user agents you should have explicit rules for:
GPTBot (OpenAI's training crawler)
OAI-SearchBot (OpenAI's search-specific crawler)
ChatGPT-User (user-initiated browsing in ChatGPT)
ClaudeBot (Anthropic)
PerplexityBot (Perplexity AI)
Google-Extended (Google's AI training crawler, separate from Googlebot)
Google-Agent (user-triggered, added March 2026)
Bytespider (ByteDance)
CCBot (Common Crawl, feeds many training datasets)
AppleBot-Extended (Apple Intelligence features)
The strategic logic: blocking OAI-SearchBot or PerplexityBot reduces your visibility in ChatGPT Search and Perplexity answers. Blocking CCBot prevents data extraction by providers that send no traffic back. Each decision should be intentional.
One critical exception: Google-Agent, added to Google's official crawler list in March 2026, ignores robots.txt entirely. It acts as a proxy for human-initiated requests. If you need to restrict it, you'll need server-side authentication or rate limiting at the infrastructure level.
Step 2: Verify Content Visibility Through Server-Side Rendering
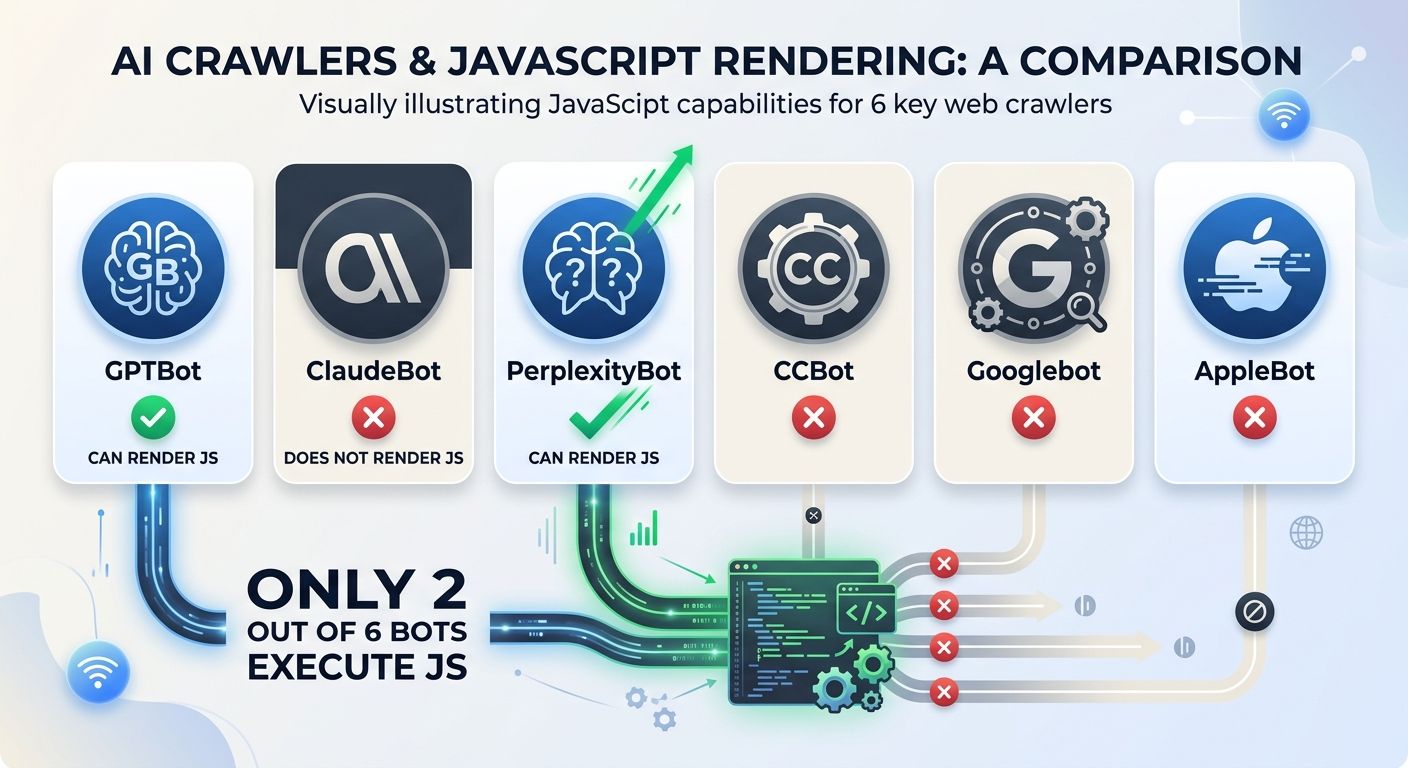
This is where the largest percentage of sites I audit fail the AI-readiness test. The data is unambiguous: only Googlebot and AppleBot execute JavaScript among major crawlers. GPTBot, ClaudeBot, PerplexityBot, and CCBot all read raw HTML only.
If your site relies on client-side rendering through React, Vue, Angular, or any other JavaScript framework, your content is invisible to four out of six major AI crawlers. That's a fundamental visibility gap for crawlability for AI search engines.
How to test this yourself:
Open your terminal and run a simple curl command against your key pages
Look at the raw HTML response (or use "View Source" in your browser, which differs from Inspect Element)
Check whether your product names, prices, service descriptions, and key claims appear in that raw HTML
If you see empty div containers, loading states, or placeholder text, AI crawlers see the same thing
Frameworks that solve this:
Next.js (React) with SSR or Static Site Generation enabled
Nuxt (Vue) with server-side rendering
Angular Universal for Angular applications
The fix isn't optional. If your revenue pages aren't in static HTML, they don't exist in the AI ecosystem. The DebugBear technical SEO checklist recommends analyzing site architecture, linking structure, and response codes as part of any audit, but the rendering layer is where AI-specific audits diverge from traditional ones.
Step 3: Map Click Depth and Eliminate Orphan Pages
The information architecture best practices that have served traditional SEO still apply, but AI crawlers amplify the penalty for violations. A clean, interconnected structure distributes ranking power and improves discoverability for both search engines and AI crawlers.
Here's the audit protocol I use:
List your critical page templates: homepage, category pages, product or service pages, blog posts, location pages
Measure click depth to revenue pages: every high-value page should be reachable within two to three clicks from the homepage. There's no universal magic number, but shallow, logical architecture helps both users and crawlers prioritize key content
Identify orphan pages: pages with zero internal links pointing to them. These are invisible to any crawler that discovers content through link traversal, which includes every AI crawler
Fix orphan pages immediately: add contextual internal links from semantically related content. A page about "commercial HVAC maintenance" should be linked from your main services page, your HVAC category page, and at least two or three relevant blog posts
For enterprise sites, this is where topical silos become critical. Group semantically related content into tightly interlinked clusters. A legal services site, for example, should have its personal injury pages linking densely to each other, separate from its corporate law cluster. This boosts crawl efficiency and signals topical authority to both traditional and AI-powered search systems.
The broader context here matters: as optimization frameworks fragment across traditional SEO, AEO, and GEO, site architecture becomes the shared foundation that all three disciplines depend on.
Step 4: Implement Complete Structured Data with Entity Relationships
Schema markup has evolved beyond rich snippet triggers. JSON-LD structured data is now used by 53% of the top 10 million sites, according to W3Techs data from early 2026. AI systems use it to understand what your content is about, who wrote it, and how it relates to known entities.
The audit here has two parts: presence and completeness.
Most sites I review have some schema in place. Very few have complete schema. "Skeleton schemas" with only a name and URL do almost nothing. You need to populate all relevant properties for each schema type.
Priority schema types for AI crawlability:
Article: include author, datePublished, dateModified, publisher, headline, and description
Organization: include sameAs links to your social profiles, Wikipedia page (if you have one), and official directory listings
Product: include price, availability, review ratings, brand, and SKU
FAQ: structure actual questions and answers your audience asks
HowTo: break processes into discrete steps with clear names and descriptions
Person (for author pages): include sameAs, jobTitle, and affiliation
The entity relationship layer is where most implementations fall short. Use sameAs to connect your Organization schema to verifiable external profiles. Use author and publisher properties to establish content provenance. AI systems are increasingly cross-referencing these relationships to determine source authority.
Research from the GEO paper published at ACM KDD 2024 found that adding statistics and data density to content improves AI visibility by 41%. Separately, Yext's analysis showed that data-rich websites earn 4.3 times more AI citations than directory-style listings. The structured data layer is how you make that richness machine-readable.
Step 5: Format Content for AI Citation Probability
How you structure your HTML content directly affects whether AI systems can extract and cite it. This goes beyond writing quality into the territory of website architecture SEO 2026 decisions at the markup level.
Specific formatting patterns that increase citation probability:
Definition lists (using dl, dt, and dd HTML elements) increase citation rates by 30 to 40% compared to equivalent information buried in paragraph text
HTML tables for comparative data, pricing, specifications, or feature matrices
Bullet points and numbered lists for processes, criteria, or options
BLUF (Bottom Line Up Front) writing structure: state your conclusion or answer first, then provide supporting detail. AI retrieval systems pull the first substantive sentence from a section far more often than they dig into paragraph three
If your content team writes in long narrative blocks with key facts scattered throughout, AI systems will struggle to extract the specific claims that would trigger a citation. The fix is structural: lead each section with the answer, then support it.
Semantic HTML reinforces this. Using proper heading hierarchy (h1 through h4 in order), section elements, article elements, and appropriate phrase-level markup (em for emphasis, abbr for abbreviations, cite for references) gives AI parsers explicit signals about content structure and importance.

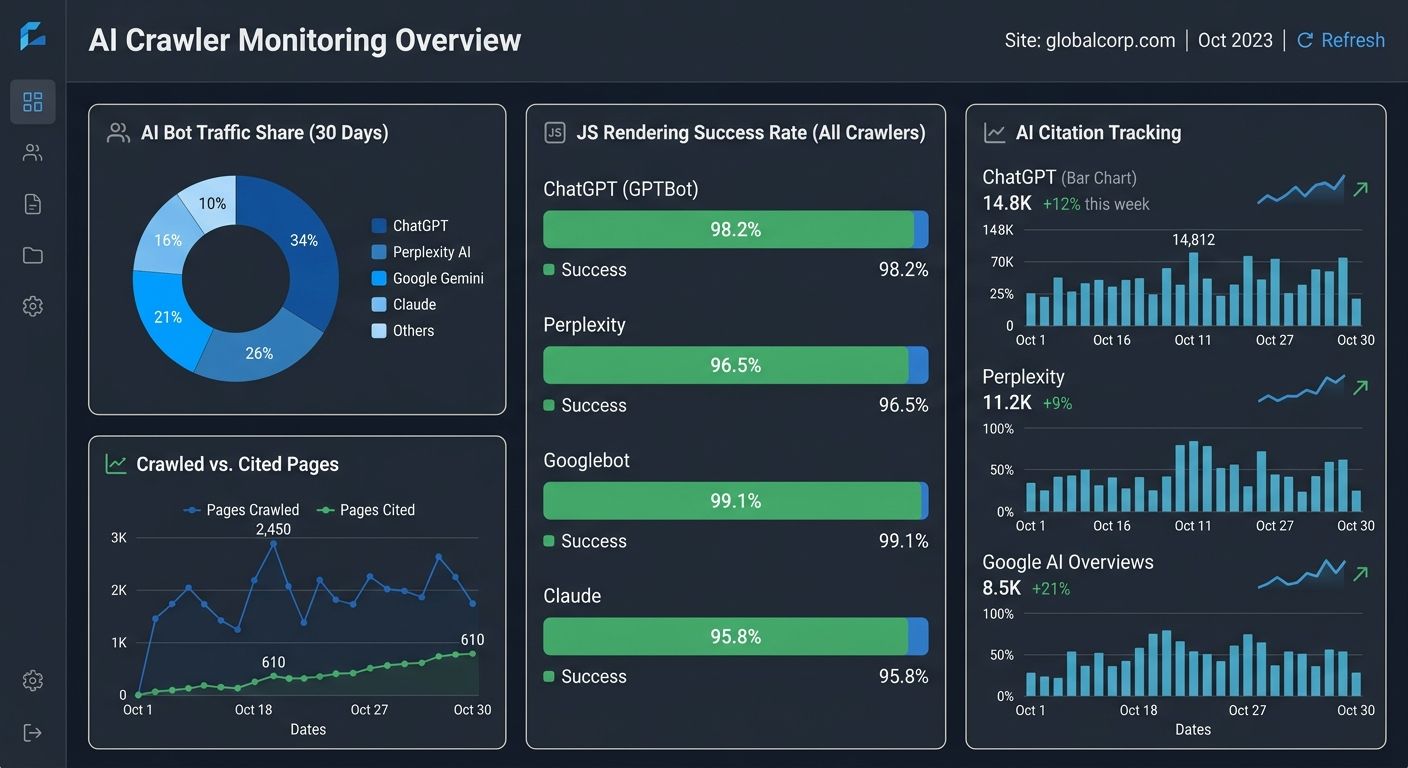
Step 6: Monitor AI Crawler Traffic and Citation Performance
You can't manage what you don't measure, and most analytics setups weren't built to track AI crawler behavior. Here's what to monitor:
Server log analysis:
Track requests from GPTBot, ClaudeBot, PerplexityBot, and other AI user agents as a percentage of total bot traffic
Monitor which pages they're hitting most frequently
Watch for crawl errors specific to AI bots (often different from Googlebot errors due to the JavaScript rendering gap)
AI citation tracking:
Check your brand presence in ChatGPT, Perplexity, Gemini, and Google AI Overviews for your target queries
Tools like Conductor's AI crawlability monitoring and LLMrefs' AI crawl checker can test whether specific pages are readable by AI bots
Track changes after architecture modifications to establish cause-and-effect
IndexNow protocol:
Google doesn't support IndexNow, but Bing, Yandex, and critically, ChatGPT (which draws from Bing's index) do. If you're updating inventory, publishing time-sensitive content, or making structural changes, IndexNow ensures near-instant propagation to the AI systems that rely on Bing's crawl data.
The measurement gap is real. I've seen agencies report strong traditional SEO performance for clients while AI visibility erodes quarter over quarter because nobody was looking at the right data. If you're evaluating how your agency tracks AI-specific metrics, the same scrutiny you'd apply to traditional SEO benchmarks should extend to this channel.
The Full Audit Checklist, Summarized
For those running this audit on your own sites or your clients' sites, here's the sequence in priority order:
robots.txt review: Confirm you have explicit rules for each AI user agent listed in Step 1. Document your allow/block rationale per crawler based on referral value
Rendering test: Curl your top 20 revenue pages and verify that all critical content appears in raw HTML without JavaScript execution
Click depth analysis: Map your highest-value pages and confirm they're reachable within three clicks from the homepage. Flag and fix all orphan pages
Structured data audit: Validate schema completeness (not just presence) for Article, Organization, Product, FAQ, and Person types. Verify entity relationships via sameAs and author properties
Content format review: Check whether key pages use definition lists, tables, and BLUF structure, or whether answers are buried in prose blocks
Monitoring setup: Confirm server logs are segmenting AI bot traffic. Set up AI citation tracking for priority queries
Effective AI crawler optimization requires continuous monitoring and performance analysis, not a one-time audit. I'd recommend running this quarterly, or after any major CMS migration, redesign, or JavaScript framework change.
What Still Isn't Settled
Several open questions make this space genuinely uncertain, and I'd be dishonest if I presented this audit as a permanent solution.
Google-Agent's relationship to traditional search rankings remains unclear. Google says it acts on behalf of users, but its crawl patterns look a lot like a training bot with extra permissions. How Google uses data collected through this agent will shape whether blocking it becomes a standard recommendation.
The value exchange with AI crawlers is still wildly unbalanced. ClaudeBot's 20,600-page-per-referral ratio means Anthropic is extracting enormous value while returning almost nothing in traffic. Whether publishers push back through legal channels, technical blocks, or negotiated licensing agreements will reshape the landscape within the next 12 to 18 months. If you've been watching how brands are disappearing from AI search recommendations, the stakes are already clear.
And the schema standard itself is evolving. The current JSON-LD vocabulary works well for structured content types, but AI systems are beginning to parse content in ways that schema.org doesn't fully capture yet. Conversational intent, multi-step task completion, and agent-driven workflows all require content structures we haven't standardized.
The architecture decisions you make today will need revisiting. Build your site structure with enough modularity that you can adapt robots.txt rules, rendering strategies, and structured data schemas as the AI crawler ecosystem matures. The sites that treat this as a fixed checklist will find themselves running the same audit again in six months, wondering why their AI visibility dropped while their traditional rankings held steady.
Marcus Webb
Digital marketing consultant and agency review specialist. With 12 years in the SEO industry, Marcus has worked with agencies of all sizes and brings an insider perspective to agency evaluations and selection strategies.
Explore more topics