The Technical SEO Handoff: What Web Developers Actually Need to Know Before Launch
Google's rendering pipeline, as of December 2025, silently excludes any page returning a non-200 HTTP status code from being rendered. No crawl, no index, no second chance. A page built with client-side JavaScript that shows users a friendly "out of stock" message on a 404? Googlebot never sees it.
 Marcus Webb··9 min read
Marcus Webb··9 min read
The Technical SEO Handoff: What Web Developers Actually Need to Know Before Launch
Google's rendering pipeline, as of December 2025, silently excludes any page returning a non-200 HTTP status code from being rendered. No crawl, no index, no second chance. A page built with client-side JavaScript that shows users a friendly "out of stock" message on a 404? Googlebot never sees it. That single change invalidated the launch strategy for every e-commerce site I audited in Q1 of this year, because the developer teams had no idea the rule existed. The developer SEO handoff had failed before the first deployment.
I've spent twelve years watching this pattern repeat. A development team builds something technically impressive, the SEO team submits a list of requirements too late in the process, and the site launches with invisible structural damage that takes months to unwind. This article dissects one of the most consequential developer SEO handoff failures I've seen play out across multiple clients simultaneously, triggered by Google's rendering changes and the INP transition, and walks through exactly what broke and why.
December 2025: Google Stops Rendering Non-200 Pages
The change itself was quiet. Google updated its rendering documentation to clarify that pages serving non-200 HTTP status codes could be excluded from the rendering pipeline entirely. For sites built on traditional server-rendered architectures, this barely mattered. For the growing number of sites using React, Vue, or Angular with client-side rendering, it was a silent disaster.
Here's what happened in practice. An e-commerce client I was advising had just completed a full site rebuild on a headless commerce platform. The development team was talented. They'd built a fast, visually polished storefront using Next.js, but with a critical configuration error: their out-of-stock product pages returned 404 status codes while still rendering a "Similar Products" widget via client-side JavaScript. The logic made sense from a UX perspective. From Google's perspective, those pages ceased to exist.
The Yotpo 2026 technical SEO guide documents this exact scenario: "If your site relies on client-side JavaScript to display user-friendly error messages or 'Recommended Products' on a 404 page, Googlebot may never see that content." The fix requires a decision tree that most developers never receive in a handoff document. Permanently removed products should return 404 or 410. Temporarily out-of-stock items should keep serving a 200 OK with visible "OutOfStock" schema markup and a server-rendered alternatives section.
The client lost indexation on roughly 1,400 product pages during their first three weeks post-launch. Those pages had been accumulating link equity for years under the old platform. A proper technical SEO implementation checklist delivered during the wireframe phase would have flagged this in ten minutes.
What made it worse: the SEO agency the client was working with had submitted their requirements as a PDF attachment to a Slack message, fourteen days before launch. The development team read it, found it vague ("ensure proper status codes"), and moved on. I've written before about how enterprise SEO strategies collapse without organizational alignment, and this was a textbook example. The requirements existed. The translation between SEO language and developer language didn't.
The Client-Side Rendering Trap That Killed Indexation
The rendering problem extended well beyond status codes. The same client's product listing pages (PLPs) were pulling product data, prices, and availability from an API after the initial HTML loaded. This is standard architecture for headless commerce platforms. It's also a direct path to partial indexation.
Google's crawler does execute JavaScript, but it queues pages for rendering and processes them later. CognitiveSEO's technical audit framework identifies this rendering delay as one of the top crawlability risks for modern sites. During that queue time, Googlebot sees only the initial HTML shell. If your product names, prices, descriptions, and internal links exist only in JavaScript-rendered components, they may never make it into the index.
The solution is straightforward in principle: use SSR for every page that needs to rank. In practice, this requires the SEO team to identify which pages need organic visibility before the architecture decisions are made, not after. The handoff document needs to include a page-type inventory — a table listing every template type, its rendering requirement, and its target indexation status. Here's what that looks like:
Product detail pages (PDPs): SSR required, index and follow, full JSON-LD structured data
Category/listing pages (PLPs): SSR required, index and follow, breadcrumb schema
Faceted navigation pages (color, size, price filters): Noindex or canonicalize to parent category
Cart, checkout, account pages: CSR acceptable, noindex
Blog/content pages: SSR required, index and follow, Article schema
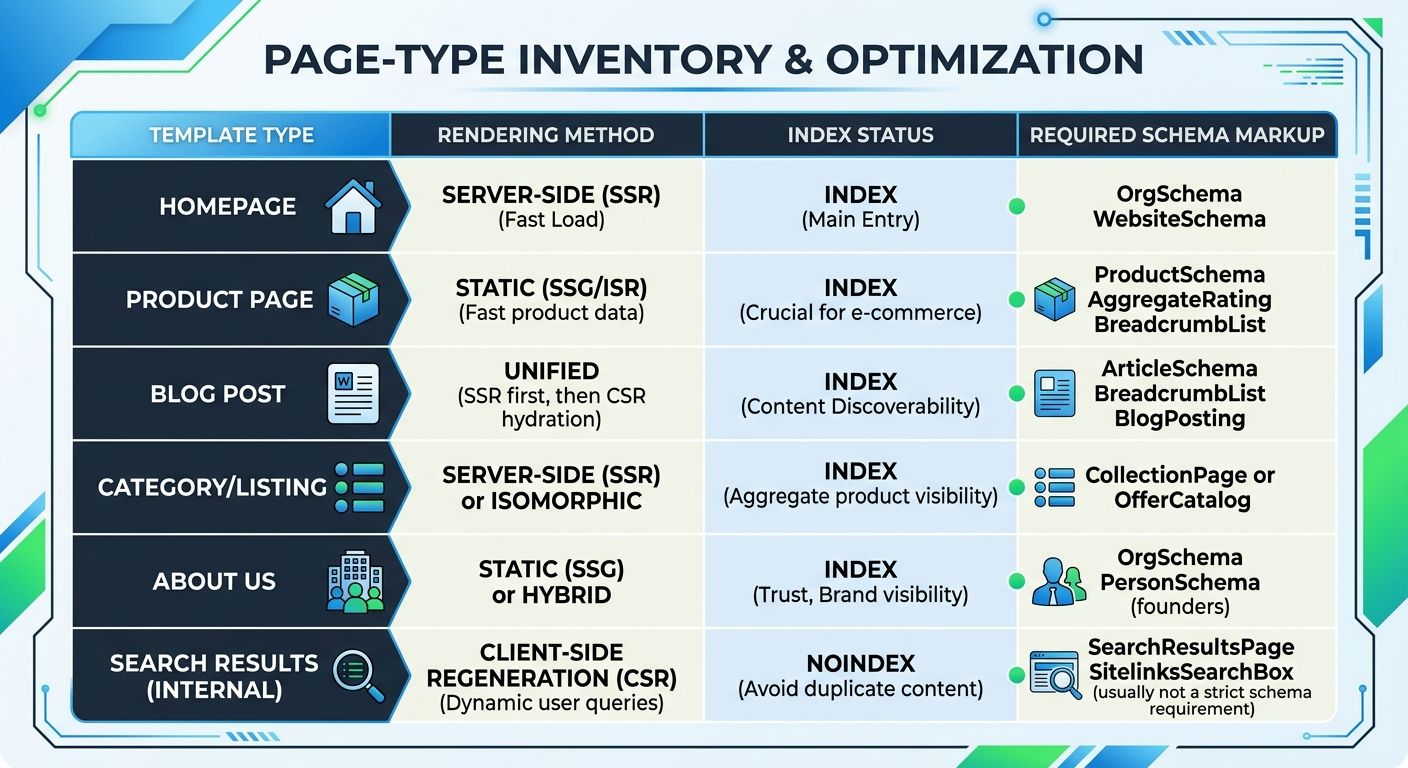
This inventory needs to exist in the same project management tool the developers use. A PDF attached to an email is where SEO requirements go to die.
INP Replaced FID, and the JavaScript Budget Didn't Exist
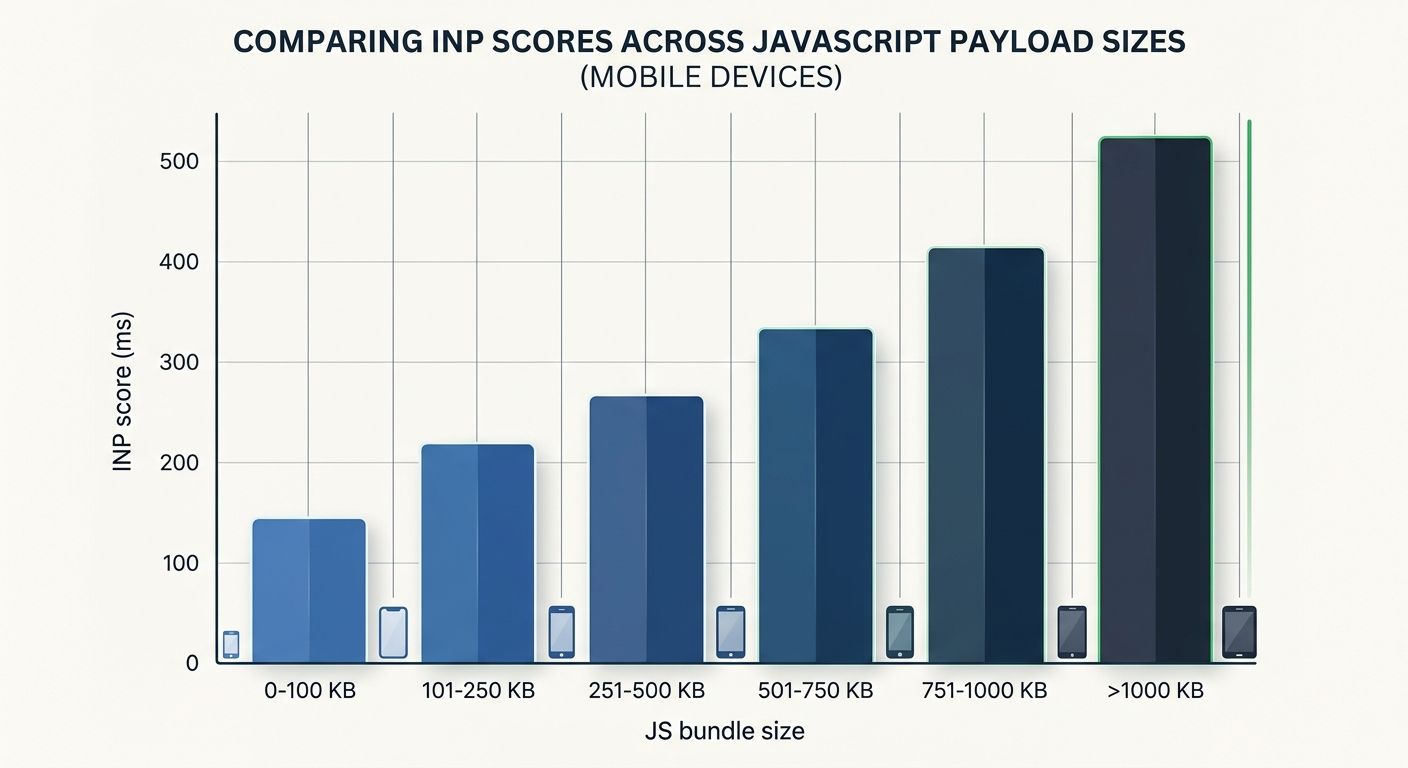
While the rendering failures were eating indexation, a parallel problem was destroying the pages that did get indexed. Interaction to Next Paint (INP) replaced First Input Delay as Google's Core Web Vitals responsiveness metric, and the thresholds are unforgiving. Good INP is under 200 milliseconds. Poor INP — the kind that acts as a confirmed negative ranking signal — sits above 500 milliseconds.
The client's site scored 720ms on mobile INP in staging. The cause was a familiar one: the main thread was blocked by heavy JavaScript bundles executing during user interactions. Every time a visitor tapped a filter, opened a size selector, or added an item to cart, the browser froze for nearly three-quarters of a second.
Google's own Core Web Vitals documentation and the web.dev performance guides are explicit about this: field measurement (real user data) is the only way to accurately capture INP scores, because lab tests don't replicate the variety of devices, network conditions, and interaction patterns your actual visitors experience. The development team had been testing exclusively in Chrome DevTools on their M-series MacBooks. Their real users were on three-year-old Android phones over LTE.
Site speed optimization for developers means setting a JavaScript budget before a single component is built. For this client, the budget should have been:
Total JavaScript payload per page: under 300KB compressed
Time to First Byte (TTFB): under 300ms
Main-thread blocking time during interaction: under 150ms
Third-party script count: capped at 4 (analytics, consent manager, chat widget, payment processor)
The third-party scripts were the worst offender. The marketing team had added a heat-mapping tool, two A/B testing platforms, a chatbot, a review widget, and a retargeting pixel — all loading synchronously on every page. Nobody had coordinated with the developers on a script loading strategy because nobody thought of it as an SEO concern.
This is where the handoff document needs teeth. I tell every client I work with: the SEO team's performance requirements must be written as acceptance criteria in the sprint tickets. "Page must score below 200ms INP on a Moto G Power over 4G" is a testable, enforceable requirement. "Optimize page speed" is not.
If you've been through a site migration and experienced the pain of preserving hard-won rankings, you know that performance regressions during a rebuild can undo years of work overnight. INP failures compound with indexation failures to create a double penalty that's brutal to recover from.
Schema Drift, Bot Governance, and the Smartphone Crawler
The final layer of this failure involved three problems that are individually minor but collectively devastating when they compound at launch.
Schema drift is a term the Yotpo guide uses to describe what happens when your structured data (JSON-LD) contradicts your visible page content. The client's product pages had JSON-LD markup generated at build time showing "InStock" for products that were dynamically updated to "Sold Out" via AJAX after page load. Google saw the contradiction. The fix is automated testing that validates JSON-LD values against rendered DOM elements before every deployment, but this testing didn't exist in the CI/CD pipeline because nobody asked for it.
Bot governance is the second problem. The client's robots.txt file had been copied from their old platform and contained a blanket disallow for several bot user agents, including OAI-SearchBot. This meant the site was invisible in ChatGPT Search results from day one. Meanwhile, GPTBot (which trains OpenAI's models) was allowed full access — the exact opposite of what most businesses want. The DashThis technical SEO checklist covers robots.txt configuration as a foundational audit step, but it takes on new urgency when AI search bots need explicit allow/disallow decisions.
A sensible bot governance policy for most commercial sites looks like this:
Googlebot: Allow all indexable pages
OAI-SearchBot: Allow (this powers ChatGPT Search answers)
GPTBot: Disallow (this trains language models on your content)
Google-Extended: Disallow unless you want content used in Gemini training
Bingbot: Allow (Bing's index feeds several AI answer engines)
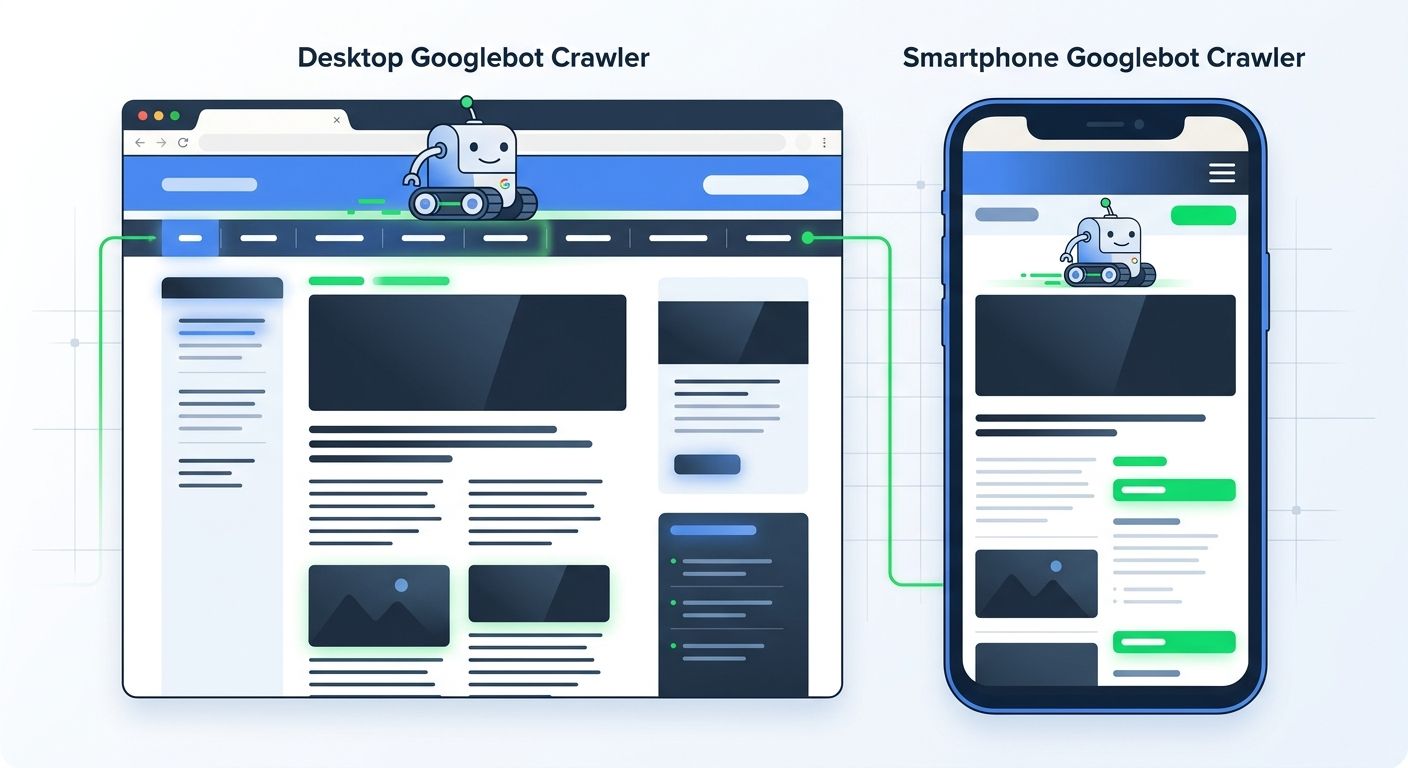
The smartphone crawler gap was the third problem. Google's mobile-first indexing documentation states that Googlebot primarily crawls with a Smartphone user agent. The client's mobile navigation used a hamburger menu that loaded its link structure via JavaScript on tap. Googlebot's smartphone crawler never saw those internal links, which meant the entire category structure was invisible to the crawler on mobile. With mobile devices accounting for 62% of web traffic, the mobile responsiveness SEO requirements for any launch must include a crawl test using the Smartphone user agent in Search Console.
The navigation links need to be present in the initial HTML. Period. A hamburger menu is fine for visual design, but the links it contains must exist in the DOM on page load, not injected after a user interaction.
If your agency is building sites for industries where image-heavy portfolios already create indexation challenges, adding a mobile crawler gap on top of those existing problems can flatline organic visibility for months.
The Handoff Document That Should Have Existed at the Wireframe Stage
The client recovered. It took seven weeks of post-launch emergency work, approximately $18,000 in additional development costs, and a significant amount of trust erosion between the marketing and engineering teams. Every fix described above could have been prevented by a single document delivered at the wireframe stage — before architecture decisions were locked in, before the component library was chosen, before the CI/CD pipeline was configured.
That document doesn't need to be long. It needs to be specific, written in developer language, and embedded in the project management workflow. Based on this case, here's the minimum viable technical SEO handoff:
Page-type inventory with rendering method (SSR vs. CSR), index status, and required schema for each template
HTTP status code decision tree for every product state (in stock, out of stock, discontinued, redirected)
JavaScript budget expressed as testable acceptance criteria (payload size, TTFB, INP threshold, third-party script cap)
robots.txt policy with explicit decisions for each major bot user agent
Schema validation requirement added to the CI/CD pipeline, checking JSON-LD against rendered DOM
Mobile crawl audit using Smartphone user agent, verifying that navigation links and key content render without JavaScript interaction
This document needs a single owner — someone who speaks both SEO and engineering fluently enough to translate between the two teams. In my experience, that person is rarely the SEO agency's account manager and rarely the lead developer. It's usually a technical SEO specialist or a senior developer who's been burned by a bad launch before.
The pattern I keep seeing across agencies of all sizes, from boutiques billing $3,000/month to enterprise shops at $25,000+, is the same. The SEO knowledge exists. The development skill exists. The translation layer between them doesn't. And the cost of that gap, as this case shows, is measured in lost indexation, degraded Core Web Vitals, invisible AI search presence, and a seven-figure revenue impact that nobody budgeted for.
The tools to prevent this are available right now. Google's Core Web Vitals report in Search Console catches INP and LCP problems in production. Lighthouse catches them in staging. Automated schema validation tools catch drift before deployment. The gap was never about tooling. The gap has always been about when the conversation happens between the people who understand search engines and the people who build websites. If that conversation starts at the wireframe, the launch goes smoothly. If it starts two weeks before go-live, you're spending $18,000 to fix what a meeting could have prevented.
Marcus Webb
Digital marketing consultant and agency review specialist. With 12 years in the SEO industry, Marcus has worked with agencies of all sizes and brings an insider perspective to agency evaluations and selection strategies.
Explore more topics